
I am Wei-Jaw (Lonian) Lee (李維釗), a first year PhD student in the depart of Graduate Institute of Communication Engineering at National Taiwan University in Taipei, Taiwan. I am a member of Music an AI Lab, under the supervision of Prof. Yi-Hsuan Yang.
My research interests lie in the field of music generation. More specifically, I am exploring the following topics:
- Multi-modalities control of music generation
- Model efficiency(training, data, and inference) in music generation
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Experience
-
May. 2025 - PresentTaiwan AILabs
 Research Intern
Research Intern
Education
-
Sep. 2023 - PresentNational Taiwan University
 Ph.D. in Communication Engineering
Ph.D. in Communication Engineering
Supervisor: Prof. Yi-Hsuan Yang -
Sep. 2018 - Jan. 2023National Yang Ming Chiao Tung University
 B.S. in Biological Science & Technology and Electrical Engineering
B.S. in Biological Science & Technology and Electrical Engineering
Honors & Awards
-
Top-Tier Doctoral Fellowship, College of Electrical Engineering and Computer Science2025
-
Ministry of Education (MOE) Doctoral Scholarship2025
Selected Publications (view all )
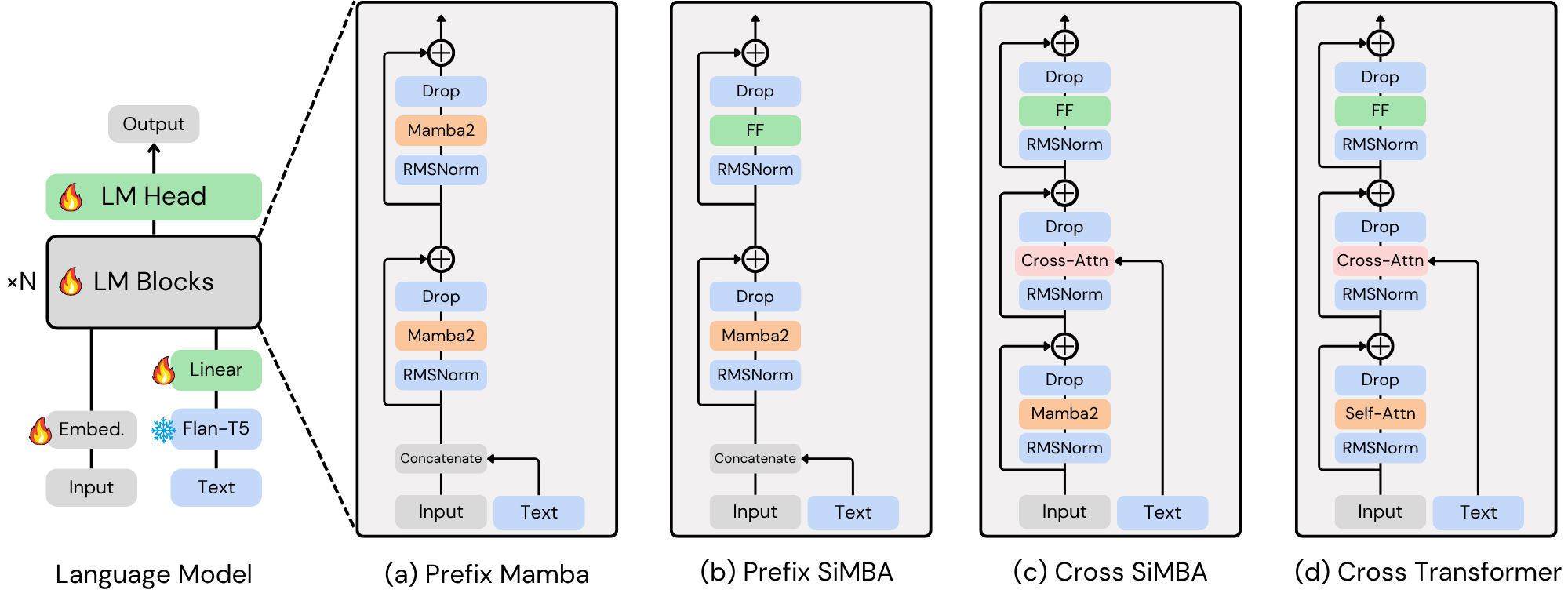
Training-Efficient Text-to-Music Generation with State-Space Modeling
Wei-Jaw Lee, Fang-Chih Hsieh, Xuanjun Chen, Fang-Duo Tsai, Yi-Hsuan Yang
Under review 2026
We propose a hybrid Auto-Regressive (AR) and Non-Auto-Regressive (NAR) architecture for coarse-to-fine music generation. Our approach employs a State-Space Model (SSM) as the language model to generate coarse tokens, followed by a pre-trained diffusion model for fine-grained refinement. By leveraging the linear scaling of SSMs, our model achieves significantly higher training efficiency compared to traditional Transformer-based architectures.
Training-Efficient Text-to-Music Generation with State-Space Modeling
Wei-Jaw Lee, Fang-Chih Hsieh, Xuanjun Chen, Fang-Duo Tsai, Yi-Hsuan Yang
Under review 2026
We propose a hybrid Auto-Regressive (AR) and Non-Auto-Regressive (NAR) architecture for coarse-to-fine music generation. Our approach employs a State-Space Model (SSM) as the language model to generate coarse tokens, followed by a pre-trained diffusion model for fine-grained refinement. By leveraging the linear scaling of SSMs, our model achieves significantly higher training efficiency compared to traditional Transformer-based architectures.
Exploring State-Space-Model Based Language Model in Music Generation
Wei-Jaw Lee, Fang-Chih Hsieh, Xuanjun Chen, Fang-Duo Tsai, Yi-Hsuan Yang
International Society for Music Information Retrieval, Late Breaking Demo 2025
We investigates the potential of Mamba-based State Space Models (SSMs) as an efficient alternative to Transformers for text-to-music generation. By adopting a single-layer codebook representation and adapting the SiMBA architecture into a decoder, the proposed model achieves significantly faster convergence and produces outputs closer to the ground truth under limited-resource settings. The findings demonstrate that SSMs offer a promising path for developing efficient and expressive music language models that maintain high performance with lower computational overhead.
Exploring State-Space-Model Based Language Model in Music Generation
Wei-Jaw Lee, Fang-Chih Hsieh, Xuanjun Chen, Fang-Duo Tsai, Yi-Hsuan Yang
International Society for Music Information Retrieval, Late Breaking Demo 2025
We investigates the potential of Mamba-based State Space Models (SSMs) as an efficient alternative to Transformers for text-to-music generation. By adopting a single-layer codebook representation and adapting the SiMBA architecture into a decoder, the proposed model achieves significantly faster convergence and produces outputs closer to the ground truth under limited-resource settings. The findings demonstrate that SSMs offer a promising path for developing efficient and expressive music language models that maintain high performance with lower computational overhead.
MuseControlLite: Multifunctional Music Generation with Lightweight Conditioners
Fang-Duo Tsai, Shih-Lun Wu, Wei-Jaw Lee, Sheng-Ping Yang, Bo-Rui Chen, Hao-Chung Cheng, Yi-Hsuan Yang
International Conference on Machine Learning 2025
We propose MuseControlLite, a lightweight fine-tuning mechanism that uses rotary positional embeddings and decoupled cross-attention to achieve precise, time-varying control over music generation. This model achieves superior melody accuracy while requiring nearly 7 times fewer trainable parameters than state-of-the-art ControlNet-based architectures. It is the first framework to simultaneously handle musical attribute control (melody, rhythm, and dynamics) alongside reference audio for seamless inpainting and outpainting.
MuseControlLite: Multifunctional Music Generation with Lightweight Conditioners
Fang-Duo Tsai, Shih-Lun Wu, Wei-Jaw Lee, Sheng-Ping Yang, Bo-Rui Chen, Hao-Chung Cheng, Yi-Hsuan Yang
International Conference on Machine Learning 2025
We propose MuseControlLite, a lightweight fine-tuning mechanism that uses rotary positional embeddings and decoupled cross-attention to achieve precise, time-varying control over music generation. This model achieves superior melody accuracy while requiring nearly 7 times fewer trainable parameters than state-of-the-art ControlNet-based architectures. It is the first framework to simultaneously handle musical attribute control (melody, rhythm, and dynamics) alongside reference audio for seamless inpainting and outpainting.